AVL 树和红黑树都假设所有的数据放在主存当中。而当数据量达到亿级,主存中根本存储不下,我们只能以块的形式从磁盘读取数据,与主存的访问时间相比,磁盘的 I/O 操作相当耗时,而提出 B-树的主要目的就是减少磁盘的 I/O 操作。
B树的一个节点$x$如果包含$n$个$key$,则其有$n+1$个孩子。($n$个key将其余数据划分为$n+1$个区间,每个孩子介于相应的区间中)
性质
B树所具有的的性质人如下:
- 每个节点$x$应具有如下属性:
- $x.n$即,存储在$x$节点的$key$个数
- 节点$x$的n个key以非降序排列。$x.key_1 \le x.key_2 \le \cdots \le x.key_{x.n}$
- $ x.leaf$,布尔值。用来表示x是(true)否(false)为叶子节点
- 每个非叶子节点还包括$x.n + 1$个指向其孩子的指针:$x.c_1,x.c_2,x.c_3\cdots,x.c_{x.n +1}$。叶子节点没有该定义。
- $x.key_i$对其子节点进行分割。假设$k_i$为其子节点的$key$值。则有
$$
k_1 \le x.key_1 \le k_2 \le x.key_2 \le \cdots \le x.key_{x.n} \le k_{x.n +1}
$$
4. 所有的叶子节点深度相同
5. B树的最小度数$t \ge 2$以限制每个节点所包含$key$值的个数(上下限)。
1. 除根节点外,每个节点必须至少有$t-1$个$key$。(除叶子节点外,每个节点至少有$t$个孩子)
2. 每个节点至多有$2t-1$个key。(除叶子节点外,每个节点至多有$2t$个孩子)当B树恰好拥有$2t-1$个$key$时,称该节点为满的。(结合性质5.1即B树要求半满)
一个B树的样例如下: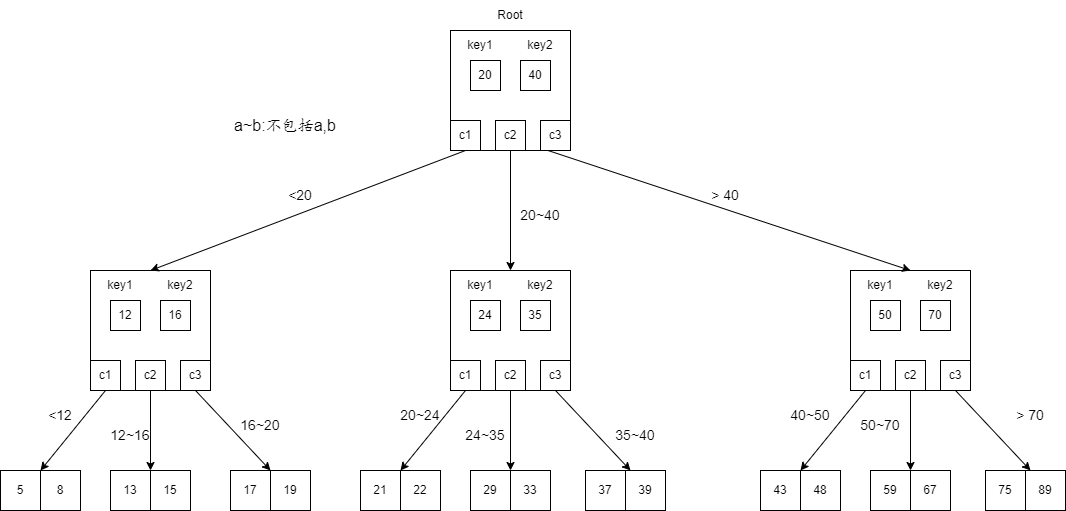
一个较为简单的B树定义
1 | class BTreeNode |
B树的高度
B树大部分操作的磁盘存取次数与B树的高度成正比。对于任意一个包含$n$个$key$,高度为$h$,最小度为$t$的B树,有
$$
h \le \log_{t}{\frac{n+1}{2} }
$$
基本操作
在此假定:B树始终在主存中,无需读取磁盘。
搜索
B树的搜索,不过是在二叉搜索树的基础上,每个节点有多个$key$值。
以上述的样例图中查找33为例。
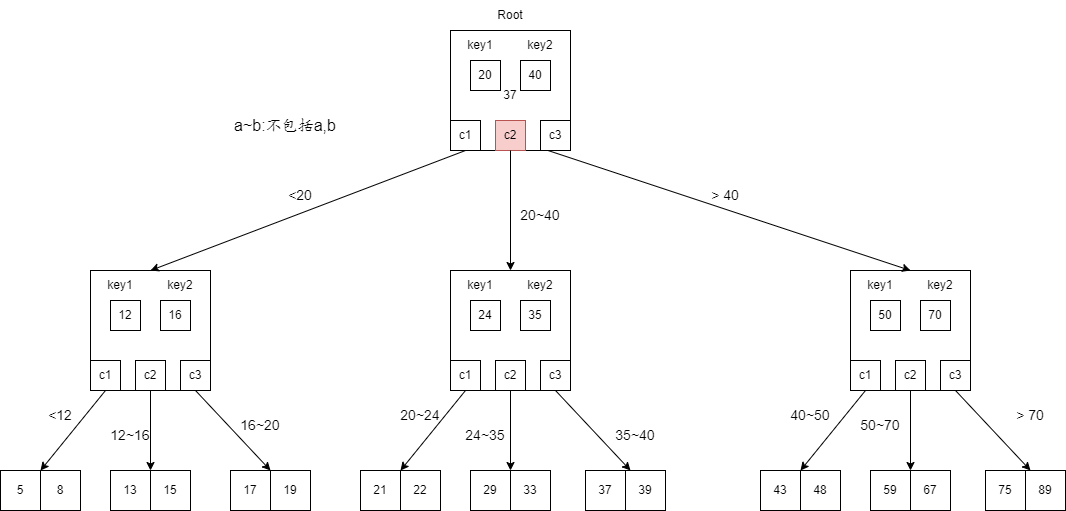
- 首先,访问根节点。先和第一个$key$值20比较,发现 $37>20$。然后与第二个$key$值40比较,此时$37<40$。于是递归到20与40之间的子节点去查找。
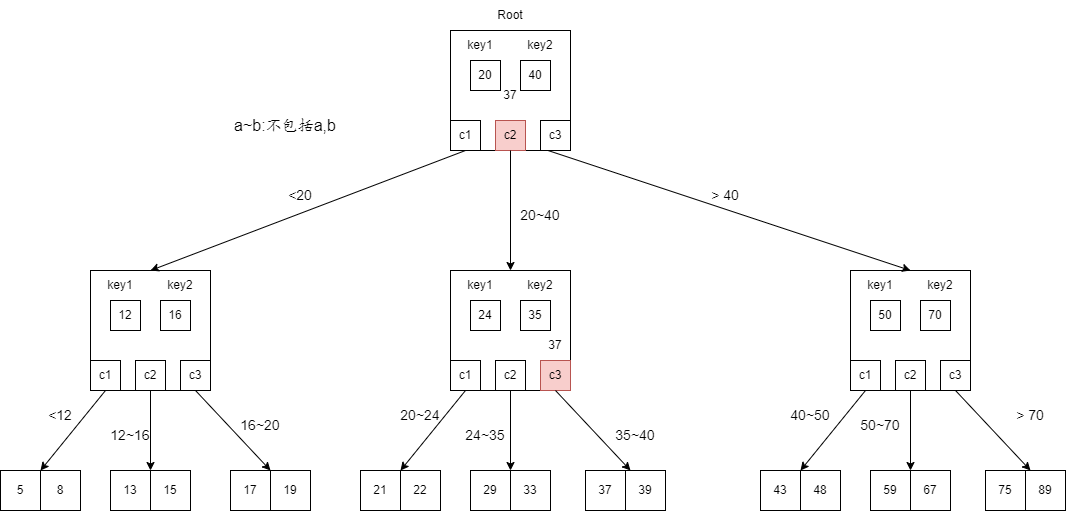
- 接着,访问$\left[24,35\right]$节点。先和第一个$key$ 24比较,发现$37>24$。然后与第二个$key$ 35比较,发现$37 > 35$。访问该节点的最后一个子节点。
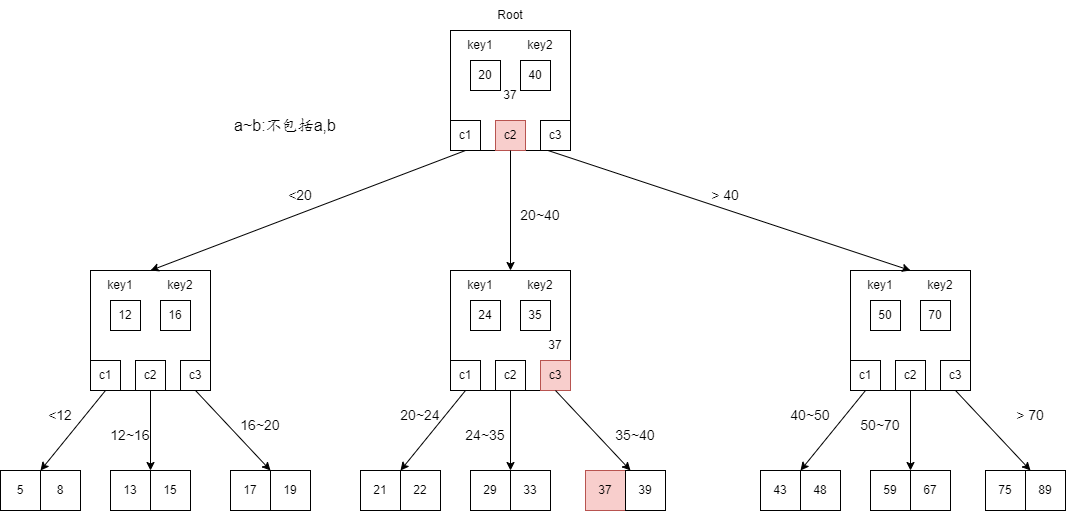
- 最后在叶子节点$\left[ 37,39\right]$中,查找到37,结束。
相关过程代码如下:插入、删除。过于复杂,先略了,有空再写。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18BTreeNode *BTreeNode::search(int k)
{
// 找到第一个大于待查找k 的key值
int i = 0;
while (i < n && k > keys[i]) {
i++;
}
// 相等即找到
if (keys[i] == k)
return this;
// 如果没有找到,且当前结点为叶子结点则无解
if (leaf == true)
return nullptr;
// 递归访问恰当的子代
return C[i]->search(k);
}